💡 总结与小计 (Summary & Key Takeaways)
本章核心主旨: 本章将软件系统的组织比作城市的管理,强调了在系统架构层面保持“整洁”的重要性。作者主张软件系统应该像城市一样,通过抽象和模块化来管理复杂性。核心思想是将系统的构造(Startup/Construction)与系统的使用(Runtime/Use)分离开来。
关键知识点 (Key Takeaways):
- 构造与使用分离:不要把对象的创建逻辑(启动过程)和正常的业务逻辑混合在一起。
- 依赖注入 (DI):使用依赖注入(如 Spring 框架)将对象的创建和依赖关系的装配权移交给专门的容器(Main 或 IoC 容器),从而实现控制反转。
- 横切关注点 (Cross-Cutting Concerns):利用 AOP (面向切面编程) 来处理日志、安全、事务等跨越多个对象的通用逻辑,避免业务代码被污染。
- POJO (Plain Old Java Objects):坚持使用纯净的 Java 对象编写核心业务逻辑,使其独立于特定的框架(如旧版 EJB),提高可测试性和灵活性。
- 增量式架构:架构不需要在开始时就进行“大而全的预先设计”(BDUF)。只要保持关注点分离,架构可以随着需求迭代演进。
- DSL (领域特定语言):使用 DSL 缩短领域概念与代码实现之间的沟通差距。
📖 中英对照翻译
第 11 章 Systems (系统)
by Dr. Kevin Dean Wampler

“Complexity kills. It sucks the life out of developers, it makes products difficult to plan, build, and test.”
—Ray Ozzie, CTO, Microsoft Corporation
“复杂性是杀手。它吸干了开发者的生命力,让产品难以规划、构建和测试。”
——雷·奥兹 (Ray Ozzie),微软公司首席技术官
HOW WOULD YOU BUILD A CITY?
你会如何建造一座城市?
Could you manage all the details yourself? Probably not. Even managing an existing city is too much for one person. Yet, cities work (most of the time). They work because cities have teams of people who manage particular parts of the city, the water systems, power systems, traffic, law enforcement, building codes, and so forth. Some of those people are responsible for the big picture, while others focus on the details. 你能独自管理所有的细节吗?恐怕不能。即便是管理一座现有的城市,对一个人来说也太难了。然而,城市(大部分时间)是正常运转的。它们之所以能运转,是因为城市有各级团队在管理城市的特定部分:水务系统、电力系统、交通、执法、建筑规范等等。有些人负责统筹全局,而另一些人则专注于细节。
Cities also work because they have evolved appropriate levels of abstraction and modularity that make it possible for individuals and the “components” they manage to work effectively, even without understanding the big picture. 城市能运转还在于其演化出了适当的抽象等级和模块化,这使得个人及其管理的“组件”即便在不了解全局的情况下,也能有效地工作。
Although software teams are often organized like that too, the systems they work on often don’t have the same separation of concerns and levels of abstraction. Clean code helps us achieve this at the lower levels of abstraction. In this chapter let us consider how to stay clean at higher levels of abstraction, the system level. 虽然软件团队通常也是这样组织的,但他们所开发的系统往往缺乏同样的关注点分离和抽象等级。整洁的代码帮助我们在较低的抽象层级上实现了这一点。在本章中,我们将探讨如何在更高的抽象层级——即系统层级——上保持整洁。
SEPARATE CONSTRUCTING A SYSTEM FROM USING IT
将系统的构造与使用分开
First, consider that construction is a very different process from use. As I write this, there is a new hotel under construction that I see out my window in Chicago. Today it is a bare concrete box with a construction crane and elevator bolted to the outside. The busy people there all wear hard hats and work clothes. In a year or so the hotel will be finished. The crane and elevator will be gone. The building will be clean, encased in glass window walls and attractive paint. The people working and staying there will look a lot different too. 首先,我们要认识到,构造与使用是两个截然不同的过程。在我写这段话时,透过我在芝加哥的窗户,能看到一家正在建设中的新酒店。今天它还是一个光秃秃的混凝土盒子,外面固定着建筑起重机和升降机。那里忙碌的人们都戴着安全帽,穿着工作服。大约一年后,酒店将完工。起重机和升降机将消失。大楼将变得整洁,包裹在玻璃幕墙和漂亮的涂料中。在那里工作和住宿的人看起来也会大不相同。
Software systems should separate the startup process, when the application objects are constructed and the dependencies are “wired” together, from the runtime logic that takes over after startup. 软件系统应将启动过程——即应用程序对象被创建且依赖关系被“装配”在一起的时候——与启动后接管的运行时逻辑分离开来。
The startup process is a concern that any application must address. It is the first concern that we will examine in this chapter. The separation of concerns is one of the oldest and most important design techniques in our craft. 启动过程是任何应用程序都必须处理的一个关注点。这是我们本章要审视的第一个关注点。关注点分离是我们这一行中最古老也是最重要的设计技巧之一。
Unfortunately, most applications don’t separate this concern. The code for the startup process is ad hoc and it is mixed in with the runtime logic. Here is a typical example: 不幸的是,大多数应用程序并没有分离这一关注点。启动过程的代码往往是临时凑合的,并且与运行时逻辑混杂在一起。这是一个典型的例子:
public Service getService() {
if (service == null)
service = new MyServiceImpl(…); // Good enough default for most cases?
return service;
}This is the LAZY INITIALIZATION/EVALUATION idiom, and it has several merits. We don’t incur the overhead of construction unless we actually use the object, and our startup times can be faster as a result. We also ensure that null is never returned. 这就是延迟初始化/赋值(LAZY INITIALIZATION/EVALUATION)惯用手法,它有几个优点。除非我们真的使用该对象,否则不会产生构造的开销,因此启动速度可能会更快。我们还能确保永远不会返回 null。
However, we now have a hard-coded dependency on MyServiceImpl and everything its constructor requires (which I have elided). We can’t compile without resolving these dependencies, even if we never actually use an object of this type at runtime! 然而,我们现在硬编码依赖了 MyServiceImpl 及其构造函数所需的一切(我已省略)。即便我们在运行时从未真正使用过该类型的对象,如果不解决这些依赖关系,我们也无法进行编译!
Testing can be a problem. If MyServiceImpl is a heavyweight object, we will need to make sure that an appropriate TEST DOUBLE1 or MOCK OBJECT gets assigned to the service field before this method is called during unit testing. Because we have construction logic mixed in with normal runtime processing, we should test all execution paths (for example, the null test and its block). Having both of these responsibilities means that the method is doing more than one thing, so we are breaking the Single Responsibility Principle in a small way. 测试也会成为问题。如果 MyServiceImpl 是一个重量级对象,我们需要确保在单元测试中调用此方法之前,将适当的测试替身(TEST DOUBLE)或模拟对象(MOCK OBJECT)赋值给 service 字段。因为我们将构造逻辑与正常的运行时处理混合在了一起,我们就必须测试所有的执行路径(例如 null 检查及其代码块)。同时承担这两项职责意味着该方法做的事情不止一件,因此我们在某种程度上违反了单一职责原则。
- [Mezzaros07].
Perhaps worst of all, we do not know whether MyServiceImpl is the right object in all cases. I implied as much in the comment. Why does the class with this method have to know the global context? Can we ever really know the right object to use here? Is it even possible for one type to be right for all possible contexts? 也许最糟糕的是,我们不知道 MyServiceImpl 是否在所有情况下都是正确的对象。我在注释中暗示了这一点。为什么包含此方法的类必须知道全局上下文?我们真的能确定这里该使用哪个正确的对象吗?是否存在一种类型能适用于所有可能的上下文?
One occurrence of LAZY-INITIALIZATION isn’t a serious problem, of course. However, there are normally many instances of little setup idioms like this in applications. Hence, the global setup strategy (if there is one) is scattered across the application, with little modularity and often significant duplication. 当然,偶尔出现一次延迟初始化并不是什么严重的问题。然而,应用程序中通常会有许多类似的小型设置惯用手法。因此,全局设置策略(如果有的话)就会分散在应用程序各处,缺乏模块化,并且通常伴随着大量的重复。
If we are diligent about building well-formed and robust systems, we should never let little, convenient idioms lead to modularity breakdown. The startup process of object construction and wiring is no exception. We should modularize this process separately from the normal runtime logic and we should make sure that we have a global, consistent strategy for resolving our major dependencies. 如果我们致力于构建结构良好且健壮的系统,就不应让微小、便捷的惯用手法导致模块化的崩溃。对象构造和装配的启动过程也不例外。我们应该将此过程与正常的运行时逻辑分离开来,并确保我们有一个全局、一致的策略来解决主要的依赖关系。
Separation of Main
Main 的分离
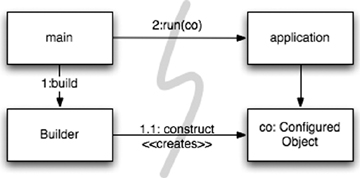
One way to separate construction from use is simply to move all aspects of construction to main, or modules called by main, and to design the rest of the system assuming that all objects have been constructed and wired up appropriately. (See Figure 11-1.) 分离构造与使用的一种方法是简单地将构造的所有方面都移至 main,或由 main 调用的模块中,并基于“所有对象都已正确构造和装配”的假设来设计系统的其余部分。(见图 11-1。)
The flow of control is easy to follow. The main function builds the objects necessary for the system, then passes them to the application, which simply uses them. Notice the direction of the dependency arrows crossing the barrier between main and the application. They all go one direction, pointing away from main. This means that the application has no knowledge of main or of the construction process. It simply expects that everything has been built properly. 控制流很容易跟踪。main 函数构建系统所需的对象,然后将它们传递给应用程序,应用程序只需使用它们。注意跨越 main 和应用程序之间屏障的依赖箭头的方向。它们都是单向的,指向远离 main 的方向。这意味着应用程序对 main 或构造过程一无所知。它只是期望一切都已正确构建。
Factories
工厂
Sometimes, of course, we need to make the application responsible for when an object gets created. For example, in an order processing system the application must create the LineItem instances to add to an Order. In this case we can use the ABSTRACT FACTORY2 pattern to give the application control of when to build the LineItems, but keep the details of that construction separate from the application code. (See Figure 11-2.) 当然,有时我们需要让应用程序负责确定对象创建的时机。例如,在订单处理系统中,应用程序必须创建 LineItem(订单项)实例以添加到 Order(订单)中。在这种情况下,我们可以使用抽象工厂(ABSTRACT FACTORY)模式,让应用程序控制何时构建 LineItems,但将构建的细节与应用程序代码隔离开来。(见图 11-2。)
Figure 11-1 Separating construction in main() (图 11-1 在 main() 中分离构造)
- [GOF].
Figure 11-2 Separation construction with factory (图 11-2 使用工厂分离构造)
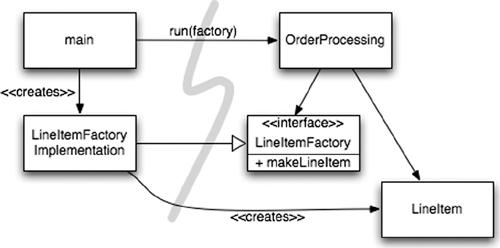
Again notice that all the dependencies point from main toward the OrderProcessing application. This means that the application is decoupled from the details of how to build a LineItem. That capability is held in the LineItemFactoryImplementation, which is on the main side of the line. And yet the application is in complete control of when the LineItem instances get built and can even provide application-specific constructor arguments. 再次注意,所有的依赖关系都从 main 指向 OrderProcessing 应用程序。这意味着应用程序与如何构建 LineItem 的细节解耦了。这种能力由位于 main 这一侧的 LineItemFactoryImplementation 持有。然而,应用程序完全控制着 LineItem 实例何时被构建,甚至可以提供特定于应用程序的构造函数参数。
Dependency Injection
依赖注入
A powerful mechanism for separating construction from use is Dependency Injection (DI), the application of Inversion of Control (IoC) to dependency management.3 Inversion of Control moves secondary responsibilities from an object to other objects that are dedicated to the purpose, thereby supporting the Single Responsibility Principle. In the context of dependency management, an object should not take responsibility for instantiating dependencies itself. Instead, it should pass this responsibility to another “authoritative” mechanism, thereby inverting the control. Because setup is a global concern, this authoritative mechanism will usually be either the “main” routine or a special-purpose container. 分离构造与使用的一种强大机制是依赖注入(Dependency Injection, DI),即控制反转(Inversion of Control, IoC)在依赖管理中的应用。控制反转将次要职责从一个对象转移到致力于此目的的其他对象上,从而支持单一职责原则。在依赖管理的背景下,对象不应负责实例化其自身的依赖项。相反,它应将此职责移交给另一个“权威”机制,从而反转控制。因为设置(setup)是一个全局关注点,这种权威机制通常是 main 例程或专用的容器。
- See, for example, [Fowler].
JNDI lookups are a “partial” implementation of DI, where an object asks a directory server to provide a “service” matching a particular name. JNDI 查找是 DI 的一种“部分”实现,其中对象请求目录服务器提供与特定名称匹配的“服务”。
MyService myService = (MyService)(jndiContext.lookup(“NameOfMyService”));The invoking object doesn’t control what kind of object is actually returned (as long it implements the appropriate interface, of course), but the invoking object still actively resolves the dependency. 调用对象并不控制实际返回什么样的对象(当然,前提是它实现了适当的接口),但调用对象仍然在主动解析依赖关系。
True Dependency Injection goes one step further. The class takes no direct steps to resolve its dependencies; it is completely passive. Instead, it provides setter methods or constructor arguments (or both) that are used to inject the dependencies. During the construction process, the DI container instantiates the required objects (usually on demand) and uses the constructor arguments or setter methods provided to wire together the dependencies. Which dependent objects are actually used is specified through a configuration file or programmatically in a special-purpose construction module. 真正的依赖注入更进一步。类不采取任何直接步骤来解析其依赖项;它是完全被动的。相反,它提供 setter 方法或构造函数参数(或两者兼有),用于注入依赖项。在构造过程中,DI 容器实例化所需的对象(通常是按需),并使用提供的构造函数参数或 setter 方法将依赖关系装配在一起。实际使用哪些依赖对象是通过配置文件或在专用构造模块中以编程方式指定的。
The Spring Framework provides the best known DI container for Java.4 You define which objects to wire together in an XML configuration file, then you ask for particular objects by name in Java code. We will look at an example shortly. Spring Framework 提供了 Java 中最著名的 DI 容器。你在 XML 配置文件中定义要装配在一起的对象,然后在 Java 代码中按名称请求特定的对象。稍后我们将看一个例子。
- See [Spring]. There is also a Spring.NET framework.
But what about the virtues of LAZY-INITIALIZATION? This idiom is still sometimes useful with DI. First, most DI containers won’t construct an object until needed. Second, many of these containers provide mechanisms for invoking factories or for constructing proxies, which could be used for LAZY-EVALUATION and similar optimizations.5 但是延迟初始化的优点呢?这种惯用手法在 DI 中有时仍然有用。首先,大多数 DI 容器直到需要时才会构造对象。其次,许多容器提供了调用工厂或构造代理的机制,这些机制可用于延迟赋值和类似的优化。
- Don’t forget that lazy instantiation/evaluation is just an optimization and perhaps premature!
- 别忘了延迟实例化/赋值只是一种优化,而且可能是过早优化!
SCALING UP
扩容 (Scaling Up)
Cities grow from towns, which grow from settlements. At first the roads are narrow and practically nonexistent, then they are paved, then widened over time. Small buildings and empty plots are filled with larger buildings, some of which will eventually be replaced with skyscrapers. 城市由城镇发展而来,城镇由定居点发展而来。起初道路狭窄甚至根本不存在,后来铺设了路面,随着时间的推移又被加宽。小建筑和空地被更大的建筑填满,其中一些最终会被摩天大楼取代。
At first there are no services like power, water, sewage, and the Internet (gasp!). These services are also added as the population and building densities increase. 起初没有电力、供水、污水处理和互联网(天哪!)等服务。这些服务也是随着人口和建筑密度的增加而添加的。
This growth is not without pain. How many times have you driven, bumper to bumper through a road “improvement” project and asked yourself, “Why didn’t they build it wide enough the first time!?” 这种增长并非没有痛苦。有多少次你驾驶在正如火如荼进行道路“改善”工程的拥堵路段,不仅问自己:“为什么他们第一次不把它建得够宽呢!?”
But it couldn’t have happened any other way. Who can justify the expense of a six-lane highway through the middle of a small town that anticipates growth? Who would want such a road through their town? 但这不可能以其他方式发生。谁能证明在一个预期会增长的小镇中间修建六车道高速公路的费用是合理的?谁会希望这样一条路穿过他们的城镇?
It is a myth that we can get systems “right the first time.” Instead, we should implement only today’s stories, then refactor and expand the system to implement new stories tomorrow. This is the essence of iterative and incremental agility. Test-driven development, refactoring, and the clean code they produce make this work at the code level. 我们要一次就把系统“做对”,这是一个神话。相反,我们应该只实现今天的用户故事,然后重构和扩展系统以实现明天的故事。这就是迭代和增量敏捷的本质。测试驱动开发、重构以及它们产生的整洁代码使这在代码层面上行之有效。
But what about at the system level? Doesn’t the system architecture require preplanning? Certainly, it can’t grow incrementally from simple to complex, can it? 但是在系统层面上呢?系统架构不需要预先规划吗?它当然不能从简单增量式地发展到复杂,是吗?
Software systems are unique compared to physical systems. Their architectures can grow incrementally, if we maintain the proper separation of concerns. 与物理系统相比,软件系统是独特的。如果我们保持适当的关注点分离,它们的架构是可以增量式增长的。
The ephemeral nature of software systems makes this possible, as we will see. Let us first consider a counterexample of an architecture that doesn’t separate concerns adequately. 软件系统短暂易变的特性使这成为可能,正如我们将看到的。让我们首先考虑一个未能充分分离关注点的架构反例。
The original EJB1 and EJB2 architectures did not separate concerns appropriately and thereby imposed unnecessary barriers to organic growth. Consider an Entity Bean for a persistent Bank class. An entity bean is an in-memory representation of relational data, in other words, a table row. 最初的 EJB1 和 EJB2 架构没有适当地分离关注点,因此对有机增长造成了不必要的障碍。考虑一个用于持久化 Bank 类的实体 Bean (Entity Bean)。实体 Bean 是关系数据的内存表示,换句话说,就是数据库表的一行。
First, you had to define a local (in process) or remote (separate JVM) interface, which clients would use. Listing 11-1 shows a possible local interface: 首先,你必须定义客户端将使用的本地(进程内)或远程(独立的 JVM)接口。代码清单 11-1 展示了一个可能的本地接口:
Listing 11-1 An EJB2 local interface for a Bank EJB (代码清单 11-1 Bank EJB 的 EJB2 本地接口)
package com.example.banking;
import java.util.Collections;
import javax.ejb.*;
public interface BankLocal extends java.ejb.EJBLocalObject {
String getStreetAddr1() throws EJBException;
String getStreetAddr2() throws EJBException;
String getCity() throws EJBException;
String getState() throws EJBException;
String getZipCode() throws EJBException;
void setStreetAddr1(String street1) throws EJBException;
void setStreetAddr2(String street2) throws EJBException;
void setCity(String city) throws EJBException;
void setState(String state) throws EJBException;
void setZipCode(String zip) throws EJBException;
Collection getAccounts() throws EJBException;
void setAccounts(Collection accounts) throws EJBException;
void addAccount(AccountDTO accountDTO) throws EJBException;
}I have shown several attributes for the Bank’s address and a collection of accounts that the bank owns, each of which would have its data handled by a separate Account EJB. Listing 11-2 shows the corresponding implementation class for the Bank bean. 我展示了银行地址的几个属性以及银行拥有的账户集合,每个账户的数据都将由单独的 Account EJB 处理。代码清单 11-2 展示了 Bank bean 相应的实现类。
Listing 11-2 The corresponding EJB2 Entity Bean Implementation (代码清单 11-2 相应的 EJB2 实体 Bean 实现)
package com.example.banking;
import java.util.Collections;
import javax.ejb.*;
public abstract class Bank implements javax.ejb.EntityBean {
// Business logic…
public abstract String getStreetAddr1();
public abstract String getStreetAddr2();
public abstract String getCity();
public abstract String getState();
public abstract String getZipCode();
public abstract void setStreetAddr1(String street1);
public abstract void setStreetAddr2(String street2);
public abstract void setCity(String city);
public abstract void setState(String state);
public abstract void setZipCode(String zip);
public abstract Collection getAccounts();
public abstract void setAccounts(Collection accounts);
public void addAccount(AccountDTO accountDTO) {
InitialContext context = new InitialContext();
AccountHomeLocal accountHome = context.lookup(”AccountHomeLocal”);
AccountLocal account = accountHome.create(accountDTO);
Collection accounts = getAccounts();
accounts.add(account);
}
// EJB container logic
public abstract void setId(Integer id);
public abstract Integer getId();
public Integer ejbCreate(Integer id) { … }
public void ejbPostCreate(Integer id) { … }
// The rest had to be implemented but were usually empty:
public void setEntityContext(EntityContext ctx) {}
public void unsetEntityContext() {}
public void ejbActivate() {}
public void ejbPassivate() {}
public void ejbLoad() {}
public void ejbStore() {}
public void ejbRemove() {}
}I haven’t shown the corresponding LocalHome interface, essentially a factory used to create objects, nor any of the possible Bank finder (query) methods you might add. 我没有展示相应的 LocalHome 接口,它本质上是用于创建对象的工厂,也没有展示你可能添加的任何 Bank 查找器(查询)方法。
Finally, you had to write one or more XML deployment descriptors that specify the object-relational mapping details to a persistence store, the desired transactional behavior, security constraints, and so on. 最后,你必须编写一个或多个 XML 部署描述符,以指定到持久化存储的对象关系映射细节、所需的事务行为、安全约束等等。
The business logic is tightly coupled to the EJB2 application “container.” You must subclass container types and you must provide many lifecycle methods that are required by the container. 业务逻辑与 EJB2 应用程序“容器”紧密耦合。你必须继承容器类型,并且必须提供许多容器所需的生命周期方法。
Because of this coupling to the heavyweight container, isolated unit testing is difficult. It is necessary to mock out the container, which is hard, or waste a lot of time deploying EJBs and tests to a real server. Reuse outside of the EJB2 architecture is effectively impossible, due to the tight coupling. 由于与重量级容器的这种耦合,隔离单元测试变得非常困难。有必要模拟容器,但这很难,或者浪费大量时间将 EJB 和测试部署到真实服务器上。由于紧密耦合,在 EJB2 架构之外的重用实际上是不可能的。
Finally, even object-oriented programming is undermined. One bean cannot inherit from another bean. Notice the logic for adding a new account. It is common in EJB2 beans to define “data transfer objects” (DTOs) that are essentially “structs” with no behavior. This usually leads to redundant types holding essentially the same data, and it requires boilerplate code to copy data from one object to another. 最后,甚至面向对象编程也受到了破坏。一个 bean 不能继承另一个 bean。注意添加新账户的逻辑。在 EJB2 bean 中定义“数据传输对象”(DTO)是很常见的,它们本质上是没有行为的“结构体”。这通常导致保存基本相同数据的冗余类型,并且需要样板代码将数据从一个对象复制到另一个对象。
Cross-Cutting Concerns
横切关注点
The EJB2 architecture comes close to true separation of concerns in some areas. For example, the desired transactional, security, and some of the persistence behaviors are declared in the deployment descriptors, independently of the source code. EJB2 架构在某些领域接近于真正的关注点分离。例如,所需的事务、安全和部分持久化行为在部署描述符中声明,独立于源代码。
Note that concerns like persistence tend to cut across the natural object boundaries of a domain. You want to persist all your objects using generally the same strategy, for example, using a particular DBMS6 versus flat files, following certain naming conventions for tables and columns, using consistent transactional semantics, and so on. 请注意,像持久化这样的关注点倾向于切分(cut across)领域的自然对象边界。你希望使用大致相同的策略持久化所有对象,例如,使用特定的 DBMS 而非纯文本文件,遵循特定的表和列命名约定,使用一致的事务语义等等。
- Database management system.
In principle, you can reason about your persistence strategy in a modular, encapsulated way. Yet, in practice, you have to spread essentially the same code that implements the persistence strategy across many objects. We use the term cross-cutting concerns for concerns like these. Again, the persistence framework might be modular and our domain logic, in isolation, might be modular. The problem is the fine-grained intersection of these domains. 原则上,你可以以模块化、封装的方式推演你的持久化策略。然而,在实践中,你不得不将实现持久化策略的、本质上相同的代码分散到许多对象中。我们使用术语横切关注点(cross-cutting concerns)来描述这类关注点。同样,持久化框架可能是模块化的,我们的领域逻辑在隔离状态下也可能是模块化的。问题在于这些领域的细粒度交叉。
In fact, the way the EJB architecture handled persistence, security, and transactions, “anticipated” aspect-oriented programming (AOP),7 which is a general-purpose approach to restoring modularity for cross-cutting concerns. 事实上,EJB 架构处理持久化、安全性和事务的方式,“预示”了面向切面编程(AOP),这是一种旨在恢复横切关注点模块化的通用方法。
- See [AOSD] for general information on aspects and [AspectJ]] and [Colyer] for AspectJ-specific information.
In AOP, modular constructs called aspects specify which points in the system should have their behavior modified in some consistent way to support a particular concern. This specification is done using a succinct declarative or programmatic mechanism. 在 AOP 中,被称为切面(aspects)的模块化结构指定了系统中哪些点应该以某种一致的方式修改其行为,以支持特定的关注点。这种规范是使用简洁的声明式或编程机制完成的。
Using persistence as an example, you would declare which objects and attributes (or patterns thereof) should be persisted and then delegate the persistence tasks to your persistence framework. The behavior modifications are made noninvasively8 to the target code by the AOP framework. Let us look at three aspects or aspect-like mechanisms in Java. 以持久化为例,你会声明哪些对象和属性(或其模式)应该被持久化,然后将持久化任务委托给你的持久化框架。行为修改是由 AOP 框架非侵入式地对目标代码进行的。让我们看看 Java 中的三种切面或类切面机制。
- Meaning no manual editing of the target source code is required.
JAVA PROXIES
Java 代理
Java proxies are suitable for simple situations, such as wrapping method calls in individual objects or classes. However, the dynamic proxies provided in the JDK only work with interfaces. To proxy classes, you have to use a byte-code manipulation library, such as CGLIB, ASM, or Javassist.9 Java 代理适用于简单的情况,例如在单个对象或类中包装方法调用。然而,JDK 提供的动态代理仅适用于接口。要代理类,你必须使用字节码操作库,如 CGLIB、ASM 或 Javassist。
- See [CGLIB], [ASM], and [Javassist].
Listing 11-3 shows the skeleton for a JDK proxy to provide persistence support for our Bank application, covering only the methods for getting and setting the list of accounts. 代码清单 11-3 展示了一个 JDK 代理的骨架,用于为我们的 Bank 应用程序提供持久化支持,仅涵盖获取和设置账户列表的方法。
Listing 11-3 JDK Proxy Example (代码清单 11-3 JDK 代理示例)
// Bank.java (suppressing package names…)
import java.utils.*;
// The abstraction of a bank.
public interface Bank {
Collection<Account> getAccounts();
void setAccounts(Collection<Account> accounts);
}
// BankImpl.java
import java.utils.*;
// The “Plain Old Java Object” (POJO) implementing the abstraction.
public class BankImpl implements Bank {
private List<Account> accounts;
public Collection<Account> getAccounts() {
return accounts;
}
public void setAccounts(Collection<Account> accounts) {
this.accounts = new ArrayList<Account>();
for (Account account: accounts) {
this.accounts.add(account);
}
}
}
// BankProxyHandler.java
import java.lang.reflect.*;
import java.util.*;
// “InvocationHandler” required by the proxy API.
public class BankProxyHandler implements InvocationHandler {
private Bank bank;
public BankHandler (Bank bank) {
this.bank = bank;
}
// Method defined in InvocationHandler
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
String methodName = method.getName();
if (methodName.equals(”getAccounts”)) {
bank.setAccounts(getAccountsFromDatabase());
return bank.getAccounts();
} else if (methodName.equals(”setAccounts”)) {
bank.setAccounts((Collection<Account>) args[0]);
setAccountsToDatabase(bank.getAccounts());
return null;
} else {
…
}
}
// Lots of details here:
protected Collection<Account> getAccountsFromDatabase() { … }
protected void setAccountsToDatabase(Collection<Account> accounts) { … }
}
// Somewhere else…
Bank bank = (Bank) Proxy.newProxyInstance(
Bank.class.getClassLoader(),
new Class[] { Bank.class },
new BankProxyHandler(new BankImpl()));We defined an interface Bank, which will be wrapped by the proxy, and a Plain-Old Java Object (POJO), BankImpl, that implements the business logic. (We will revisit POJOs shortly.) 我们定义了一个接口 Bank,它将被代理包装,以及一个实现业务逻辑的普通 Java 对象 (POJO) BankImpl。(我们稍后会重温 POJO。)
The Proxy API requires an InvocationHandler object that it calls to implement any Bank method calls made to the proxy. Our BankProxyHandler uses the Java reflection API to map the generic method invocations to the corresponding methods in BankImpl, and so on. Proxy API 需要一个 InvocationHandler 对象,它会被调用以实现对代理进行的任何 Bank 方法调用。我们的 BankProxyHandler 使用 Java 反射 API 将通用方法调用映射到 BankImpl 中的相应方法,依此类推。
There is a lot of code here and it is relatively complicated, even for this simple case.10 Using one of the byte-manipulation libraries is similarly challenging. This code “volume” and complexity are two of the drawbacks of proxies. They make it hard to create clean code! Also, proxies don’t provide a mechanism for specifying system-wide execution “points” of interest, which is needed for a true AOP solution.11 这里有很多代码,而且相对复杂,即使是对于这个简单的例子。使用字节码操作库也同样具有挑战性。这种代码“体量”和复杂性是代理的两个缺点。它们让人难以编写整洁的代码!此外,代理不提供用于指定系统范围内感兴趣的执行“点”的机制,而这对于真正的 AOP 解决方案是必需的。
- For more detailed examples of the Proxy API and examples of its use, see, for example, [Goetz].
- AOP is sometimes confused with techniques used to implement it, such as method interception and “wrapping” through proxies. The real value of an AOP system is the ability to specify systemic behaviors in a concise and modular way.
PURE JAVA AOP FRAMEWORKS
纯 Java AOP 框架
Fortunately, most of the proxy boilerplate can be handled automatically by tools. Proxies are used internally in several Java frameworks, for example, Spring AOP and JBoss AOP, to implement aspects in pure Java.12 In Spring, you write your business logic as Plain-Old Java Objects. POJOs are purely focused on their domain. They have no dependencies on enterprise frameworks (or any other domains). Hence, they are conceptually simpler and easier to test drive. The relative simplicity makes it easier to ensure that you are implementing the corresponding user stories correctly and to maintain and evolve the code for future stories. 幸运的是,大部分代理样板代码可以通过工具自动处理。代理在多个 Java 框架(例如 Spring AOP 和 JBoss AOP)内部使用,以在纯 Java 中实现切面。在 Spring 中,你将业务逻辑编写为普通 Java 对象 (POJOs)。POJO 纯粹关注其领域。它们不依赖于企业级框架(或任何其他领域)。因此,它们在概念上更简单,更容易进行测试驱动开发。相对的简单性使得更容易确保你正确实现了相应的用户故事,并为未来的故事维护和演进代码。
- See [Spring] and [JBoss]. “Pure Java” means without the use of AspectJ.
You incorporate the required application infrastructure, including cross-cutting concerns like persistence, transactions, security, caching, failover, and so on, using declarative configuration files or APIs. In many cases, you are actually specifying Spring or JBoss library aspects, where the framework handles the mechanics of using Java proxies or byte-code libraries transparently to the user. These declarations drive the dependency injection (DI) container, which instantiates the major objects and wires them together on demand. 你使用声明式配置文件或 API 来整合所需的应用程序基础设施,包括持久化、事务、安全、缓存、故障转移等横切关注点。在许多情况下,你实际上是在指定 Spring 或 JBoss 的库切面,框架会对用户透明地处理使用 Java 代理或字节码库的机制。这些声明驱动了依赖注入 (DI) 容器,该容器按需实例化主要对象并将它们装配在一起。
Listing 11-4 shows a typical fragment of a Spring V2.5 configuration file, app.xml13: 代码清单 11-4 展示了 Spring V2.5 配置文件 app.xml 的典型片段:
Listing 11-4 Spring 2.X configuration file (代码清单 11-4 Spring 2.X 配置文件)
<beans>
…
<bean id=”appDataSource”
class=”org.apache.commons.dbcp.BasicDataSource”
destroy-method=”close”
p:driverClassName=”com.mysql.jdbc.Driver”
p:url=”jdbc:mysql://localhost:3306/mydb”
p:username=”me”/>
<bean id=”bankDataAccessObject”
class=”com.example.banking.persistence.BankDataAccessObject”
p:dataSource-ref=”appDataSource”/>
<bean id=”bank”
class=”com.example.banking.model.Bank”
p:dataAccessObject-ref=”bankDataAccessObject”/>
…
</beans>Each “bean” is like one part of a nested “Russian doll,” with a domain object for a Bank proxied (wrapped) by a data accessor object (DAO), which is itself proxied by a JDBC driver data source. (See Figure 11-3.) 每个“bean”就像是嵌套的“俄罗斯套娃”的一部分,一个 Bank 领域对象被数据访问对象 (DAO) 代理(包装),而 DAO 本身又被 JDBC 驱动程序数据源代理。(见图 11-3。)
Figure 11-3 The “Russian doll” of decorators (图 11-3 装饰器的“俄罗斯套娃”)
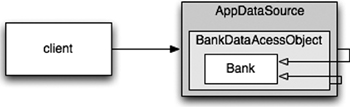
The client believes it is invoking getAccounts() on a Bank object, but it is actually talking to the outermost of a set of nested DECORATOR14 objects that extend the basic behavior of the Bank POJO. We could add other decorators for transactions, caching, and so forth. 客户端认为它正在调用 Bank 对象上的 getAccounts(),但实际上它是与一组嵌套的装饰器(DECORATOR)对象中最外层的一个进行对话,这些装饰器扩展了 Bank POJO 的基本行为。我们可以添加其他装饰器来处理事务、缓存等。
- [GOF].
In the application, a few lines are needed to ask the DI container for the top-level objects in the system, as specified in the XML file. 在应用程序中,只需几行代码即可向 DI 容器请求 XML 文件中指定的系统顶级对象。
XmlBeanFactory bf =
new XmlBeanFactory(new ClassPathResource(”app.xml”, getClass()));
Bank bank = (Bank) bf.getBean(”bank”);Because so few lines of Spring-specific Java code are required, the application is almost completely decoupled from Spring, eliminating all the tight-coupling problems of systems like EJB2. 由于需要的 Spring 特定 Java 代码很少,应用程序几乎完全与 Spring 解耦,消除了像 EJB2 这样的系统所具有的所有紧密耦合问题。
Although XML can be verbose and hard to read,15 the “policy” specified in these configuration files is simpler than the complicated proxy and aspect logic that is hidden from view and created automatically. This type of architecture is so compelling that frameworks like Spring led to a complete overhaul of the EJB standard for version 3. EJB3 largely follows the Spring model of declaratively supporting cross-cutting concerns using XML configuration files and/or Java 5 annotations. 虽然 XML 可能冗长且难以阅读,但在这些配置文件中指定的“策略”要比那些隐藏在视野之外并自动生成的复杂代理和切面逻辑简单得多。这种类型的架构非常有吸引力,以至于像 Spring 这样的框架导致了 EJB 标准在版本 3 中的彻底改革。EJB3 在很大程度上遵循了 Spring 模式,即使用 XML 配置文件和/或 Java 5 注解来声明式地支持横切关注点。
- The example can be simplified using mechanisms that exploit convention over configuration and Java 5 annotations to reduce the amount of explicit “wiring” logic required.
- 该示例可以使用利用“约定优于配置”和 Java 5 注解的机制来简化,以减少所需的显式“装配”逻辑量。
Listing 11-5 shows our Bank object rewritten in EJB316. 代码清单 11-5 展示了我们在 EJB3 中重写的 Bank 对象。
Listing 11-5 An EBJ3 Bank EJB (代码清单 11-5 一个 EJB3 Bank EJB)
package com.example.banking.model;
import javax.persistence.*;
import java.util.ArrayList;
import java.util.Collection;
@Entity
@Table(name = “BANKS”)
public class Bank implements java.io.Serializable {
@Id @GeneratedValue(strategy=GenerationType.AUTO)
private int id;
@Embeddable // An object “inlined” in Bank’s DB row
public class Address {
protected String streetAddr1;
protected String streetAddr2;
protected String city;
protected String state;
protected String zipCode;
}
@Embedded
private Address address;
@OneToMany(cascade = CascadeType.ALL, fetch = FetchType.EAGER,
mappedBy=”bank”)
private Collection<Account> accounts = new ArrayList<Account>();
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public void addAccount(Account account) {
account.setBank(this);
accounts.add(account);
}
public Collection<Account> getAccounts() {
return accounts;
}
public void setAccounts(Collection<Account> accounts) {
this.accounts = accounts;
}
}This code is much cleaner than the original EJB2 code. Some of the entity details are still here, contained in the annotations. However, because none of that information is outside of the annotations, the code is clean, clear, and hence easy to test drive, maintain, and so on. 这段代码比原始的 EJB2 代码整洁得多。一些实体细节仍然存在,包含在注解中。然而,因为没有任何信息是在注解之外的,所以代码整洁、清晰,因此易于进行测试驱动、维护等。
Some or all of the persistence information in the annotations can be moved to XML deployment descriptors, if desired, leaving a truly pure POJO. If the persistence mapping details won’t change frequently, many teams may choose to keep the annotations, but with far fewer harmful drawbacks compared to the EJB2 invasiveness. 如果需要,可以将注解中的部分或全部持久化信息移动到 XML 部署描述符中,从而留下一个真正纯净的 POJO。如果持久化映射细节不会频繁更改,许多团队可能会选择保留注解,但相比于 EJB2 的侵入性,其有害缺点要少得多。
ASPECTJ ASPECTS
AspectJ 切面
Finally, the most full-featured tool for separating concerns through aspects is the AspectJ language,17 an extension of Java that provides “first-class” support for aspects as modularity constructs. The pure Java approaches provided by Spring AOP and JBoss AOP are sufficient for 80–90 percent of the cases where aspects are most useful. However, AspectJ provides a very rich and powerful tool set for separating concerns. The drawback of AspectJ is the need to adopt several new tools and to learn new language constructs and usage idioms. 最后,通过切面分离关注点的功能最全的工具是 AspectJ 语言,它是 Java 的一个扩展,提供将切面作为模块化结构的“一等公民”支持。Spring AOP 和 JBoss AOP 提供的纯 Java 方法足以应对 80-90% 切面最有用的情况。然而,AspectJ 提供了一套非常丰富和强大的工具集来分离关注点。AspectJ 的缺点是需要采用几种新工具,并学习新的语言结构和使用惯例。
- See [AspectJ] and [Colyer].
The adoption issues have been partially mitigated by a recently introduced “annotation form” of AspectJ, where Java 5 annotations are used to define aspects using pure Java code. Also, the Spring Framework has a number of features that make incorporation of annotation-based aspects much easier for a team with limited AspectJ experience. 最近引入的 AspectJ“注解形式”部分缓解了采用问题,其中 Java 5 注解用于使用纯 Java 代码定义切面。此外,Spring Framework 具有许多特性,使得对于 AspectJ 经验有限的团队来说,整合基于注解的切面变得容易得多。
A full discussion of AspectJ is beyond the scope of this book. See [AspectJ], [Colyer], and [Spring] for more information. 对 AspectJ 的全面讨论超出了本书的范围。更多信息请参见 [AspectJ]、[Colyer] 和 [Spring]。
TEST DRIVE THE SYSTEM ARCHITECTURE
对系统架构进行测试驱动
The power of separating concerns through aspect-like approaches can’t be overstated. If you can write your application’s domain logic using POJOs, decoupled from any architecture concerns at the code level, then it is possible to truly test drive your architecture. You can evolve it from simple to sophisticated, as needed, by adopting new technologies on demand. It is not necessary to do a Big Design Up Front18 (BDUF). In fact, BDUF is even harmful because it inhibits adapting to change, due to the psychological resistance to discarding prior effort and because of the way architecture choices influence subsequent thinking about the design. 通过类切面方法分离关注点的力量怎么强调都不为过。如果你能使用 POJO 编写应用程序的领域逻辑,并在代码层面将其与任何架构关注点解耦,那么就有可能真正地对你的架构进行测试驱动。你可以根据需要,通过按需采用新技术,将其从简单演变为复杂。没有必要进行大而全的预先设计(Big Design Up Front, BDUF)。实际上,BDUF 甚至是有害的,因为它会阻碍对变更的适应,原因在于抛弃先前努力的心理阻力,以及架构选择影响后续设计思考的方式。
- Not to be confused with the good practice of up-front design, BDUF is the practice of designing everything up front before implementing anything at all.
- 不要与良好的预先设计实践相混淆,BDUF 是指在实施任何东西之前就预先设计好一切的做法。
Building architects have to do BDUF because it is not feasible to make radical architectural changes to a large physical structure once construction is well underway.19 Although software has its own physics,20 it is economically feasible to make radical change, if the structure of the software separates its concerns effectively. 建筑师必须进行 BDUF,因为一旦施工顺利进行,对大型物理结构进行激进的架构更改是不可行的。虽然软件有其自身的物理学,但如果软件结构有效地分离了关注点,那么进行激进的更改在经济上是可行的。
- There is still a significant amount of iterative exploration and discussion of details, even after construction starts.
- The term software physics was first used by [Kolence].
This means we can start a software project with a “naively simple” but nicely decoupled architecture, delivering working user stories quickly, then adding more infrastructure as we scale up. Some of the world’s largest Web sites have achieved very high availability and performance, using sophisticated data caching, security, virtualization, and so forth, all done efficiently and flexibly because the minimally coupled designs are appropriately simple at each level of abstraction and scope. 这意味着我们可以用一个“天真简单”但解耦良好的架构开始软件项目,快速交付可工作的用户故事,然后在扩容时添加更多的基础设施。世界上一些最大的网站通过使用复杂的数据缓存、安全性、虚拟化等技术,实现了极高的可用性和性能,所有这些都完成得高效且灵活,因为最小耦合的设计在每个抽象层级和范围上都是适当简单的。
Of course, this does not mean that we go into a project “rudderless.” We have some expectations of the general scope, goals, and schedule for the project, as well as the general structure of the resulting system. However, we must maintain the ability to change course in response to evolving circumstances. 当然,这并不意味着我们“无舵”地进入项目。我们对项目的总体范围、目标和时间表,以及最终系统的一般结构有一些预期。然而,我们必须保持根据不断变化的情况改变航向的能力。
The early EJB architecture is but one of many well-known APIs that are over-engineered and that compromise separation of concerns. Even well-designed APIs can be overkill when they aren’t really needed. A good API should largely disappear from view most of the time, so the team expends the majority of its creative efforts focused on the user stories being implemented. If not, then the architectural constraints will inhibit the efficient delivery of optimal value to the customer. 早期的 EJB 架构只是众多过度设计且损害关注点分离的知名 API 之一。即使是设计良好的 API,如果并不是真正需要,也可能是杀鸡用牛刀。一个好的 API 在大部分时间里应该基本上从视野中消失,以便团队将其大部分创造性精力集中在正在实现的用户故事上。如果不是这样,那么架构约束将阻碍向客户高效交付最佳价值。
To recap this long discussion, 简要回顾这一长篇讨论:
An optimal system architecture consists of modularized domains of concern, each of which is implemented with Plain Old Java (or other) Objects. The different domains are integrated together with minimally invasive Aspects or Aspect-like tools. This architecture can be test-driven, just like the code. 最佳的系统架构由模块化的关注点领域组成,每个领域都用普通 Java(或其他)对象实现。不同的领域通过最小侵入性的切面或类切面工具集成在一起。这种架构可以像代码一样进行测试驱动。
OPTIMIZE DECISION MAKING
优化决策
Modularity and separation of concerns make decentralized management and decision making possible. In a sufficiently large system, whether it is a city or a software project, no one person can make all the decisions. 模块化和关注点分离使去中心化的管理和决策成为可能。在一个足够大的系统中,无论是城市还是软件项目,没有一个人能做出所有决定。
We all know it is best to give responsibilities to the most qualified persons. We often forget that it is also best to postpone decisions until the last possible moment. This isn’t lazy or irresponsible; it lets us make informed choices with the best possible information. A premature decision is a decision made with suboptimal knowledge. We will have that much less customer feedback, mental reflection on the project, and experience with our implementation choices if we decide too soon. 我们都知道最好将责任交给最能胜任的人。我们经常忘记,最好将决策推迟到最后时刻。这不是懒惰或不负责任;这让我们能够利用尽可能最好的信息做出明智的选择。过早的决定是在知识不充分的情况下做出的决定。如果我们决定得太早,我们拥有的客户反馈、对项目的思考以及对实施选择的经验就会少得多。
The agility provided by a POJO system with modularized concerns allows us to make optimal, just-in-time decisions, based on the most recent knowledge. The complexity of these decisions is also reduced. 由具有模块化关注点的 POJO 系统提供的敏捷性,允许我们基于最新的知识做出最佳的、恰好/及时(just-in-time)的决策。这些决策的复杂性也降低了。
USE STANDARDS WISELY, WHEN THEY ADD DEMONSTRABLE VALUE
明智地使用标准,当它们能增加可论证的价值时
Building construction is a marvel to watch because of the pace at which new buildings are built (even in the dead of winter) and because of the extraordinary designs that are possible with today’s technology. Construction is a mature industry with highly optimized parts, methods, and standards that have evolved under pressure for centuries. 建筑施工是一个令人惊叹的奇观,因为新建筑的建造速度(即使在隆冬也是如此),以及当今技术可能实现的非凡设计。建筑业是一个成熟的行业,拥有高度优化的零件、方法和标准,这些都是在数百年的压力下演变而来的。
Many teams used the EJB2 architecture because it was a standard, even when lighter-weight and more straightforward designs would have been sufficient. I have seen teams become obsessed with various strongly hyped standards and lose focus on implementing value for their customers. 许多团队使用 EJB2 架构是因为它是一个标准,即使轻量级和更简单的设计就足够了。我见过有些团队痴迷于各种大肆宣传的标准,而失去了为客户实现价值的焦点。
Standards make it easier to reuse ideas and components, recruit people with relevant experience, encapsulate good ideas, and wire components together. However, the process of creating standards can sometimes take too long for industry to wait, and some standards lose touch with the real needs of the adopters they are intended to serve. 标准使重用想法和组件、招聘具有相关经验的人员、封装好的想法以及连接组件变得更加容易。然而,制定标准的过程有时太长,行业等不起,而且一些标准与它们旨在服务的采用者的真实需求脱节。
SYSTEMS NEED DOMAIN-SPECIFIC LANGUAGES
系统需要领域特定语言
Building construction, like most domains, has developed a rich language with a vocabulary, idioms, and patterns21 that convey essential information clearly and concisely. In software, there has been renewed interest recently in creating Domain-Specific Languages (DSLs),22 which are separate, small scripting languages or APIs in standard languages that permit code to be written so that it reads like a structured form of prose that a domain expert might write. 像大多数领域一样,建筑施工已经发展出一种丰富的语言,包含词汇、惯用语和模式,可以清晰简洁地传达基本信息。在软件领域,最近人们重新对创建领域特定语言(DSLs)产生了兴趣。DSL 是独立的、小型的脚本语言或标准语言中的 API,它们允许编写出的代码读起来像领域专家可能编写的结构化散文。
- The work of [Alexander] has been particularly influential on the software community.
- See, for example, [DSL]. [JMock] is a good example of a Java API that creates a DSL.
A good DSL minimizes the “communication gap” between a domain concept and the code that implements it, just as agile practices optimize the communications within a team and with the project’s stakeholders. If you are implementing domain logic in the same language that a domain expert uses, there is less risk that you will incorrectly translate the domain into the implementation. 一个好的 DSL 最小化了领域概念与实现它的代码之间的“沟通鸿沟”,就像敏捷实践优化了团队内部以及与项目利益相关者之间的沟通一样。如果你使用领域专家使用的相同语言来实现领域逻辑,那么将领域错误地翻译成实现代码的风险就会降低。
DSLs, when used effectively, raise the abstraction level above code idioms and design patterns. They allow the developer to reveal the intent of the code at the appropriate level of abstraction. 如果使用得当,DSL 会将抽象层级提升到代码惯用语和设计模式之上。它们允许开发者在适当的抽象层级上揭示代码的意图。
Domain-Specific Languages allow all levels of abstraction and all domains in the application to be expressed as POJOs, from high-level policy to low-level details. 领域特定语言允许应用程序中的所有抽象层级和所有领域都以 POJO 的形式表达,从高层策略到底层细节。
CONCLUSION
结论
Systems must be clean too. An invasive architecture overwhelms the domain logic and impacts agility. When the domain logic is obscured, quality suffers because bugs find it easier to hide and stories become harder to implement. If agility is compromised, productivity suffers and the benefits of TDD are lost. 系统也必须是整洁的。侵入性的架构会淹没领域逻辑并影响敏捷性。当领域逻辑变得模糊时,质量就会受损,因为错误更容易隐藏,故事变得更难实现。如果敏捷性受到损害,生产力就会受损,TDD 的好处也会丧失。
At all levels of abstraction, the intent should be clear. This will only happen if you write POJOs and you use aspect-like mechanisms to incorporate other implementation concerns noninvasively. 在所有的抽象层级上,意图都应该是清晰的。只有当你编写 POJO 并使用类切面机制非侵入地整合其他实现关注点时,这才会发生。
Whether you are designing systems or individual modules, never forget to use the simplest thing that can possibly work. 无论你是在设计系统还是单个模块,永远不要忘记使用能工作的最简单的方法。